OS02: Interrupts and I/O
(Usage hints for this presentation)
This presentation is archived and will not receive further updates. Updated presentations on Operating Systems are available in the course IT Systems.
Computer Structures and Operating Systems 2023
Dr. Jens Lechtenbörger (License Information)
1. Introduction
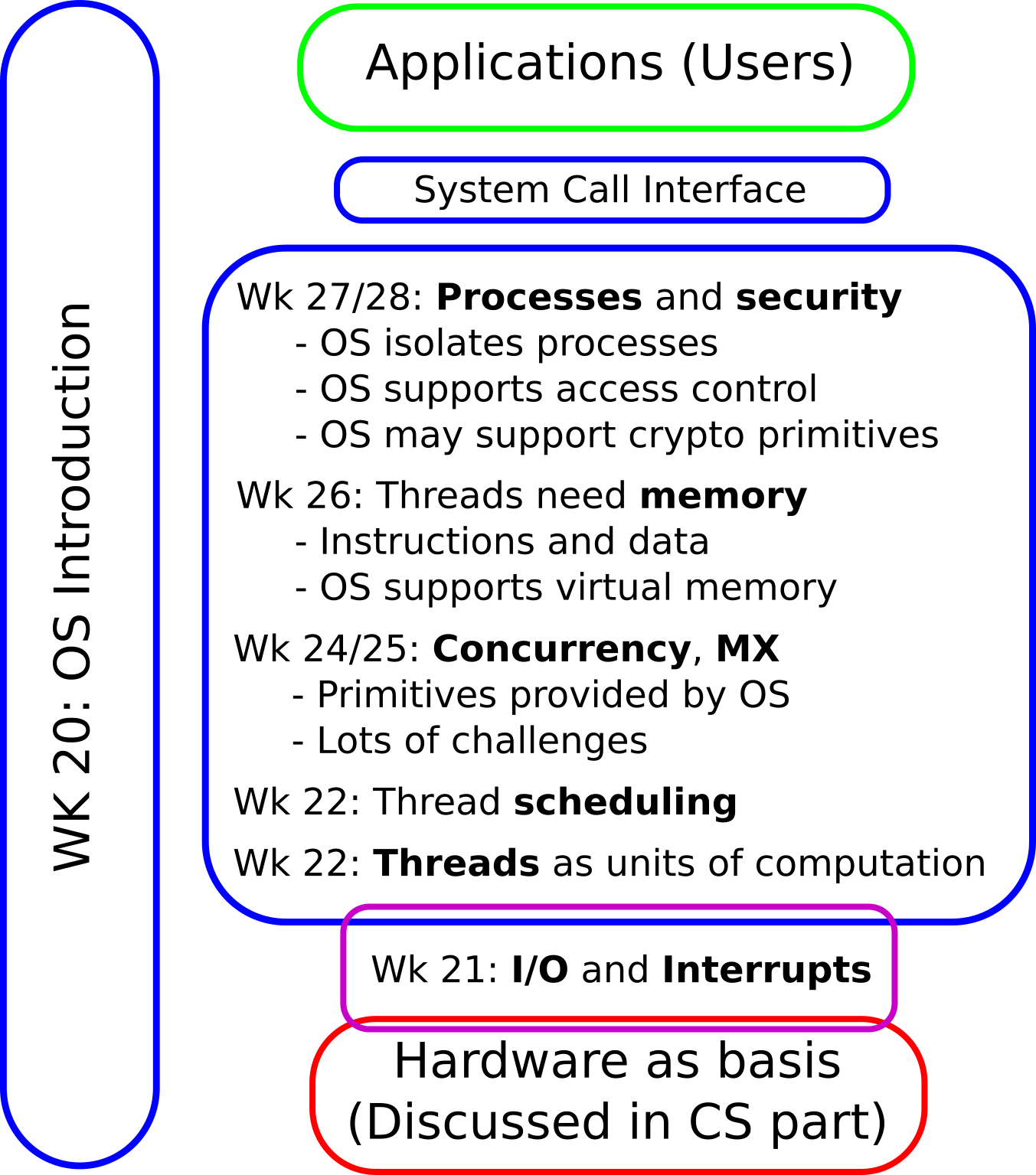
1.1. OS Plan
- OS Overview (Wk 20)
- OS Introduction (Wk 21)
- Interrupts and I/O (Wk 21)
- Threads (Wk 23)
- Thread Scheduling (Wk 24)
- Mutual Exclusion (MX) (Wk 25)
- MX in Java (Wk 25)
- MX Challenges (Wk 25)
- Virtual Memory I (Wk 26)
- Virtual Memory II (Wk 26)
- Processes (Wk 27)
- Security (Wk 28)
1.2. Today’s Core Questions
- Recall keyboard handling in Hack.
- You used a loop to wait for I/O; this is called polling.
- How can we improve I/O processing over polling?
- Why keep CPU busy in loop when nothing happens?
- With multitasking such time is wasted as other tasks could make better use of the CPU.
- Add interrupts as I/O notification mechanism.
- How to organize I/O then?
- How much overhead arises?
- (Overhead: Additional indirect computation time; makes system less efficient.)
- How to deal with “lots” of I/O events?
1.3. Learning Objectives
- Explain techniques for I/O communication
- Including sequencing of events under synchronous and asynchronous techniques (polling vs interrupts)
- Discuss dis/advantages of I/O communication techniques
- Explain (interrupt) livelock and mitigation via hybrid technique
1.4. A Note on Literature
- As an exception, this presentation is not based on [Hai19].
- In [Hai19], Section 2.5 contains some introductory paragraphs on interrupts, while Section 7.3.1 starts with explanations on privilege levels and system calls.
- Chapter 1 of [Sta14] as well of [TB15] contain introductions on interrupts and I/O, while Section 5.1 of [TB15] has additional explanations.
1.5. Retrieval Practice
- Before you continue, answer the following; ideally, without
outside help.
- How does the von Neumann architecture look like?
- How does I/O processing work with Hack?
- How to talk to an OS kernel?
- How are programs, processes, and threads related?
- What is multitasking? What are its advantages?
1.5.1. Von Neumann and Hack Architecture
1.5.2. Computations
Table of Contents
2. Hack vs Modern Computers
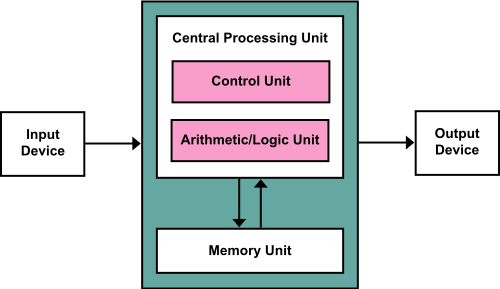
2.1. Recall: Von Neumann Architecture
{kind=link}
2.2. Hack vs Modern Computer
|
|
Hack |
Modern Computer (e.g., PC, smartphone) |
|---|---|---|
|
Memory |
• RAM for data, ROM for instructions • Physical RAM addresses • No secondary memory |
• RAM for data and instructions • Physical and virtual addresses • Memory hierarchy (disks) |
|
CPU |
• Single core • Single mode of execution • Neither cache nor MMU |
• Multi-core • Multiple protection domains • Caches and MMU |
|
I/O |
• No interrupts • Polling for I/O (recall keyboard) |
• Interrupts, DMA • Different options for I/O |
|
OS |
• Language library • Single thread, no multitasking • No virtual memory |
• Real OSs with system calls • Multitasking, scheduling • Virtual memory |
2.3. CPUs in the Real World
- Known from Hack
- Registers (addresses, data, control information)
- Instruction execution cycle (e.g., fetch, decode, execute)
Additionally
- Caching
- Cache = Small, fast memory between CPU and RAM
- (Usually, multiple levels of caches; L1, L2, …)
- Instructions and data must be in cache before CPU can access them
- Replacement policies when full (similar to those for memory management)
- Overhead for context switches, cache pollution
- Cache = Small, fast memory between CPU and RAM
- Special instructions and modes
- Access to memory and devices in kernel mode: Subsequent slide
- Enter idle state when nothing to do (save power)
- Interrupts: Later slides
- Caching
2.4. Privilege Levels/Rings/Modes
- Hierarchical protection domains of CPUs
- At least kernel mode vs. user mode (see Sec. 7.3.1
of [Hai19])
- E.g., 4 rings since Intel 80286
- Typically, ring 0 is kernel mode (most privileged), ring 3 is user mode (least privileged)
- Governed by bit pattern in special register
- E.g., 4 rings since Intel 80286
- At least kernel mode vs. user mode (see Sec. 7.3.1
of [Hai19])
- Instruction set restricted depending on mode/privilege level
- Special registers protected
- I/O, memory management protected
- OS starts in kernel mode
- Applications run in user mode
- Interrupts (system calls, traps, …) lead into kernel mode
2.5. Big Picture
- I/O devices are components that interact with the OS
- Some receive requests and deliver results
- E.g., disk, printer, network card
- Some generate events on their own
- E.g., timer/clock, keyboard, network card
- Some receive requests and deliver results
- Alternative types of I/O
- OS polls (continuously asks) for events/results
- Device triggers interrupt when event occurs or result is ready
- (Historically, special CPU input pins/bits were used to signal interrupts; now, also existing buses are used, e.g., MSI)
- CPU interrupts current computation and jumps into OS, which handles interrupt
2.5.1. Types of I/O
- With polling, I/O is called synchronous
- OS monitors I/O operation for completion
- With interrupts, I/O is called asynchronous
- OS initiates I/O
- I/O proceeds asynchronously, CPU free to perform other tasks
- Device triggers interrupt when I/O operation completed
- CPU interrupted, I/O result handled by OS
3. Polling
3.1. I/O with Polling
I/O happens synchronously while OS polls for result
3.2. Polling Observations
- Advantages
- Simple
- Fast
- Result processed as soon as it is available
- No overhead (compared to interrupts as presented subsequently)
- Result processed as soon as it is available
- Disadvantage
- Busy waiting = waiting on CPU for event to occur
- CPU time wasted if I/O is slow or infrequent
- Bad idea if wait period is “long”
- Busy waiting = waiting on CPU for event to occur
3.2.1. Polling Example: Hack Keyboard
- Program waits for user to press key
- Loop, repeatedly reading keyboard memory location until key pressed
- Recall Fill.asm
- CPU executes instructions all the time
- Even if Hack had OS with multitasking, nothing else could
be executed
- CPU time in loop is wasted
4. Interrupts
4.1. Fundamental Idea
- Interrupt: Signal to CPU
- Generated externally to CPU (signal on bus or separate pin)
- CPU stops doing whatever it did
- CPU jumps (resets program counter) to interrupt handler instead (details on following slides)
- Generated externally to CPU (signal on bus or separate pin)
- If I/O devices generate interrupts, CPU does not need
to wait for I/O completion
- OS initiates I/O operation at device
- CPU is free to do something else asynchronously during I/O execution
- At later point, I/O operation completes and device triggers
an interrupt
- OS interrupt handler acts accordingly
- OS initiates I/O operation at device
4.2. I/O with Interrupts – Overview
- Asynchronous processing of I/O
- External notifications via interrupts
4.2.1. Hypothetical Interrupt Example: Hack Keyboard (1/3)
- Suppose Hack had multitasking OS with threads and interrupts
(which it does not)
- Multiple programs could run concurrently in separate threads
- Again, wait for user to press key
- This time, thread invokes (blocking)
system call,
asking OS for next pressed key
- (Non-blocking system calls exist as well, discussed later)
- OS remembers to inform that thread about keyboard input,
blocks it
- OS takes that thread aside
- OS dispatches different thread to execute on CPU
- This time, thread invokes (blocking)
system call,
asking OS for next pressed key
4.2.2. Hypothetical Interrupt Example: Hack Keyboard (2/3)
- Eventually, key gets pressed
- Keyboard triggers interrupt
- CPU interrupts whatever it does, jumps to interrupt handler, which interacts with hardware to obtain value representing key
- OS records that value as return value of system call
- OS unblocks blocked thread
- Scheduling decision by OS determines what (unblocked) thread
to continue next
- At some point in time, maybe right now, OS chooses thread
that invoked the keyboard system call
- Thread continues with return value from system call
- At some point in time, maybe right now, OS chooses thread
that invoked the keyboard system call
- Keyboard triggers interrupt
4.2.3. Hypothetical Interrupt Example: Hack Keyboard (3/3)
- Notice:
Latency
(delay) between system call and processing of
its return value
- Latency between system call and key press
- Cannot be avoided
- In contrast to polling, with interrupts something useful can happen on the CPU during this period
- Between key press (interrupt) and return of key’s value into thread
- Processing of interrupt with overhead
- Discussed subsequently
- Resulting delay does not exist for polling
- Processing of interrupt with overhead
- Latency between system call and key press
4.3. Dijkstra on Interrupts
- “It was a great invention, but also a Box of Pandora. Because the exact moments of the interrupts were unpredictable and outside our control, the interrupt mechanism turned the computer into a nondeterministic machine with a nonreproducible behavior, and could we control such a beast?”
- “When Loopstra and Scholten suggested this feature for the X1, our next machine, I got visions of my program causing irreproducible errors and I panicked.”
4.4. Interrupts, Traps, Faults, Exceptions
- Interruption of ordinary CPU execution
- Hardware-specific, terminology not unified
- Classification
- Asynchronous, triggered externally
- Hardware interrupt (e.g., key pressed, data received)
- Timer (clocks); basic mechanism in scheduling presentation
- Hardware interrupt (e.g., key pressed, data received)
- Synchronous, triggered internally
Software interrupt
- Before execution of instruction, e.g., page fault as basic mechanism in virtual memory presentation)
- After execution of instruction (e.g., overflow)
- Asynchronous, triggered externally
4.5. Interrupts and CPUs
- OS specifies a handler for each type of interrupt and exception
- Handler = function
- Type of interrupt determined by number
- E.g., x86 processors
- Addresses of handlers stored by OS in in-memory table, the Interrupt
Descriptor Table (IDT) (synonym: Interrupt Vector (Table))
- Each table entry points to one handler/function
- CPU (each core) contains an Interrupt Descriptor Table Register
(IDTR)
- OS initializes IDTR with start address of IDT
- Addresses of handlers stored by OS in in-memory table, the Interrupt
Descriptor Table (IDT) (synonym: Interrupt Vector (Table))
4.6. Interrupt Handling
- Upon interrupt of type n:
- A context switch takes place, and (in kernel mode) the CPU
- saves state of current execution,
- uses IDTR to access IDT,
- looks up entry n in IDT, and invokes corresponding handler/function.
- Afterwards, state is restored, previous execution continued.
- A context switch takes place, and (in kernel mode) the CPU
- Context switch comes with overhead
- Save/restore state
- Cache pollution
- Cache contents unlikely to be useful in new context
- (In particular, this affects the so-called TLB, to be discussed in virtual memory presentation)
- Cache contents unlikely to be useful in new context
- Maybe scheduling (later presentation)
- With setup of new address space (virtual memory presentation)
4.7. Aside: Interrupts for System Calls
- Recall: System calls = API provided by OS kernel
- Implementation is OS and hardware specific
- Hardware specific methods to enter kernel mode
int 0x80(generic),SYSCALL(AMD),SYSENTER(Intel)
- Beyond class: Linux, Intel IA-32,
int 0x80- Software interrupt via
int 0x80leads into kernel mode - IDTR contains address of IDT
- Entry
0x80points to handler function- In the past
system_call, since 2015entry_INT80_32
- In the past
- Initialization during boot (
arch/x86/kernel/traps.c)
- Entry
- Software interrupt via
4.8. Self-Study Quiz
This task is available for self-study in Learnweb.
- Consider a networked machine that receives incoming
messages. Each of those messages requires about 4 µs CPU time
for processing. If interrupts are used, each interrupt
introduces a delay of about 6 µs (caused by different types of
overhead).
- How many messages can be processed per second with polling, how many with interrupts?
- How much time is wasted (waiting for messages to arrive) with polling in the worst case? How much spent on overhead processing with interrupts?
5. Interrupts and I/O Communication
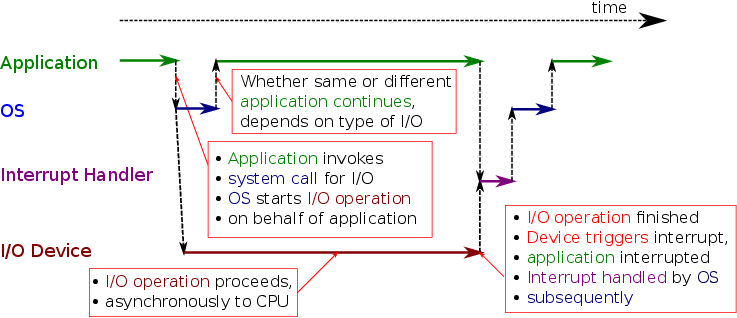
5.1. Recall: I/O with Interrupts
- Asynchronous processing of I/O
- External notifications via interrupts
5.2. Blocking vs Non-Blocking I/O
- Previous slide left open which application continues after I/O system call
- OS provides blocking and non-blocking system calls
- Blocking system call
- Application has to wait (is blocked) until I/O completed
- However, a different application may continue
- Scheduling, context switch, overhead
- Non-blocking system call
- OS initiates I/O and returns incomplete result to application
- Application continues (and is informed of or needs to check for I/O completion at later point in time)
- (Notice: This is impossible with polling)
6. I/O Processing
6.1. Latency Example (1/2)
- Goal: Explain interrupt overhead as serious challenge if interrupts are frequent
- See [LSHK09]
- Two PCs with Intel Xeon processors (2.13 GHz)
- 1 Gbps Ethernet networking cards connected via PCIe
- 1 – 2 frames may arrive per 1 µs (1 µs = one millionth second)
- For the curious
- Ethernet’s unit of transfer: frame with minimum size of 512 b
- At 1 Gbps, 1000 b need 1 µs for transfer, plus propagation and queueing delays
- Thus, 1 – 2 frames may arrive per 1 µs
- For the curious
- Interrupt per frame arrival!?
- What about 10 Gbps networking?
6.2. Latency Example (2/2)
- Numbers from [LSHK09]
- Processing of single frame takes total of 7.7 µs
- Latency breakdown according to different sources
- Hardware: ≈ 0.6 µs
- Interrupt processing: > 3 µs
- Processing of data: > 3 µs
- If one or two frames arrive per 1 µs and each frame needs 7.7 µs
processing time, something is seriously wrong
- Network data will be dropped because it arrives too fast
- The system could even crash
- Interrupt per arrival does not work
- Network data will be dropped because it arrives too fast
6.3. Interrupt Livelocks
- Livelock: Situation in which computations take place but (almost)
no progress is made
- Computation time is mostly wasted on overhead
- Interrupt livelock
- Interrupts arrive so fast that they cannot be processed any longer
- Also, not enough CPU time left for other tasks
- Interrupts served with high priority
- Context switching, cache pollution
- Nothing useful happens any more
- Also, not enough CPU time left for other tasks
- Prevent by hybrid of polling and interrupts
- E.g., NAPI
- Interrupts arrive so fast that they cannot be processed any longer
6.3.1. Starvation
- Interrupt livelock is special case of starvation
- Starvation = continued denial/lack of resource
- Under interrupt livelock, threads do not receive resource CPU (in sufficient quantities for progress) as long as “too many” interrupts are triggered
- Starvation revisiting in later presentations on scheduling and challenges for mutual exclusion
6.4. NAPI
- Linux “New API” for networking (2001), see [SOK01]
- Hybrid scheme
- Use interrupts under low load
- Utilize CPUs better
- Avoid polling for devices without data
- Utilize CPUs better
- Switch to polling under high load
- Avoid I/O overhead
- Data will be available anyways
- Avoid I/O overhead
- Use interrupts under low load
7. Outlook
7.1. When to Poll?
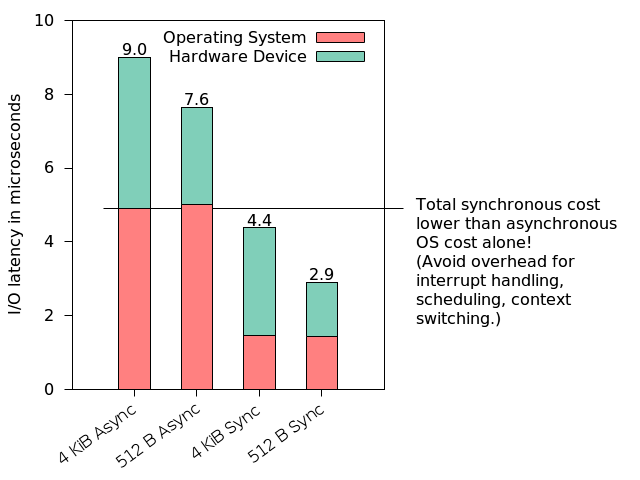
Measurements for DRAM-based storage prototype (data from [YMH12])
7.2. I/O Processing – Then and Now
- Then: Disks are slow
- Mechanical devices
- Delivered data is processed immediately by CPU
- Latency before data arrives → Interrupts beneficial
- Now: Nonvolatile memory/SCMs are fast, see [NSWW16]
- Mechanics eliminated
- Operation at network/bus speed (PCIe)
- Data can be delivered faster than processed → Polling beneficial
- Need to rethink previous techniques
- Balancing, scheduling, scaling, tiering
7.3. Call for Research
- [B17]: Attack of the Killer Microseconds
- Nanosecond latency (DRAM access when data not in CPU cache) is hidden by CPU hardware
- Out-of-order execution, branch prediction, multithreading (two threads per core)
- (However, also ongoing research to address Killer Nanoseconds [J18])
- Millisecond latency (disk I/O) is hidden by OS
- Multitasking
- What about microseconds of new generation of fast I/O devices?
- E.g., Gbps networking, flash memory
- Paper describes datacenter challenges experienced at Google
- Nanosecond latency (DRAM access when data not in CPU cache) is hidden by CPU hardware
8. Conclusions
8.1. Summary
- Interrupt handling is major OS task
- System call implementation
- I/O processing
- Timers, to be revisited for scheduling
- Polling vs interrupt-driven I/O
- Efficiency trade-off
- Interrupt livelocks
Bibliography
- [B17] Barroso, Marty, Patterson & Ranganathan, Attack of the Killer Microseconds, CACM 60(4), 48-54 (2017). https://dl.acm.org/citation.cfm?id=3015146
- [Hai19] Hailperin, Operating Systems and Middleware – Supporting Controlled Interaction, revised edition 1.3.1, 2019. https://gustavus.edu/mcs/max/os-book/
- [J18] Jonathan, Minhas, Hunter, Levandoski & Nishanov, Exploiting Coroutines to Attack the "Killer Nanoseconds", Proc. VLDB Endow. 11(11), 1702-1714 (2018). https://doi.org/10.14778/3236187.3236216
- [LSHK09] Larsen, Sarangam, Huggahalli & Kulkarni, Architectural Breakdown of End-to-End Latency in a TCP/IP Network, Int. J. Parallel Prog. 37(6), 556-571 (2009). http://link.springer.com/article/10.1007/s10766-009-0109-6
- [NSWW16] Nanavati, Schwarzkopf, Wires & Warfield, Non-volatile Storage – Implications of the Datacenter's Shifting Center, ACM Queue 13(9), (2016). https://queue.acm.org/detail.cfm?id=2874238
- [SOK01] Salim, Olsson & Kuznetsov, Beyond Softnet, in: Proceedings of the 5th Annual Linux Showcase & Conference, 2001. https://www.usenix.org/publications/library/proceedings/als01/full_papers/jamal/jamal.pdf
- [Sta14] Stallings, Operating Systems – Internals and Design Principles, Pearson, 2014.
- [TB15] Tanenbaum & Bos, Modern Operating Systems, Pearson, 2015.
- [YMH12] Yang, Minturn & Hady, When Poll is Better than Interrupt, in: FAST 2012, 2012. https://www.usenix.org/conference/fast12/when-poll-better-interrupt
License Information
This document is part of an Open Educational Resource (OER) course on Operating Systems. Source code and source files are available on GitLab under free licenses.
Except where otherwise noted, the work “OS02: Interrupts and I/O”, © 2017-2023 Jens Lechtenbörger, is published under the Creative Commons license CC BY-SA 4.0.
In particular, trademark rights are not licensed under this license. Thus, rights concerning third party logos (e.g., on the title slide) and other (trade-) marks (e.g., “Creative Commons” itself) remain with their respective holders.