Distributed Systems
(Usage hints for this presentation)
Summer Term 2023
Dr. Jens Lechtenbörger (License Information)
1. Introduction
1.1. Learning Objectives
- Explain “distributed system” and related major notions
- Definition, examples, goals and challenges
- Basic scalability techniques
- Logical time, consistency, consensus
- Contrast synchronous and asynchronous distributed systems
- Compute vector timestamps for events in asynchronous systems and reason about consistency
1.2. Context for CACS
- CACSs are distributed systems
- Distributed systems consist of multiple parts, which may reside
on different machines
- (Definitions on later slides)
- (Think of your phone: Apps that need network connectivity to work properly are part of distributed systems)
- Distributed systems consist of multiple parts, which may reside
on different machines
- Four sessions on technical aspects of CACSs
- Previously
- Git as sample distributed communication and collaboration system
- Here: Distributed systems (DSs) in general
- Upcoming
- Internet as fundamental infrastructure for DSs
- Web and e-mail as sample distributed applications
- Previously
1.3. Communication and Collaboration
- Communication frequently takes place via the Internet
- Telephony
- Instant messaging
- Social networks
- Collaboration frequently supported by tools using Internet
technologies
- All of the above means for communication
- ERP, CRM, e-learning systems
- File sharing: Sciebo, etherpad, etc.
- Programming (which subsumes file sharing): Git, subversion, etc.
- All of the above are instances of DSs
1.4. Ubiquity
- DSs are everywhere
Decentralized, heterogeneous, evolving
![Internet of Things]()
“Internet of Things” by Wilgengebroed on Flickr under CC BY 2.0; from Wikimedia Commons
- Variety of applications
- Variety of physical networks and devices
- Cloud computing, browser as access device
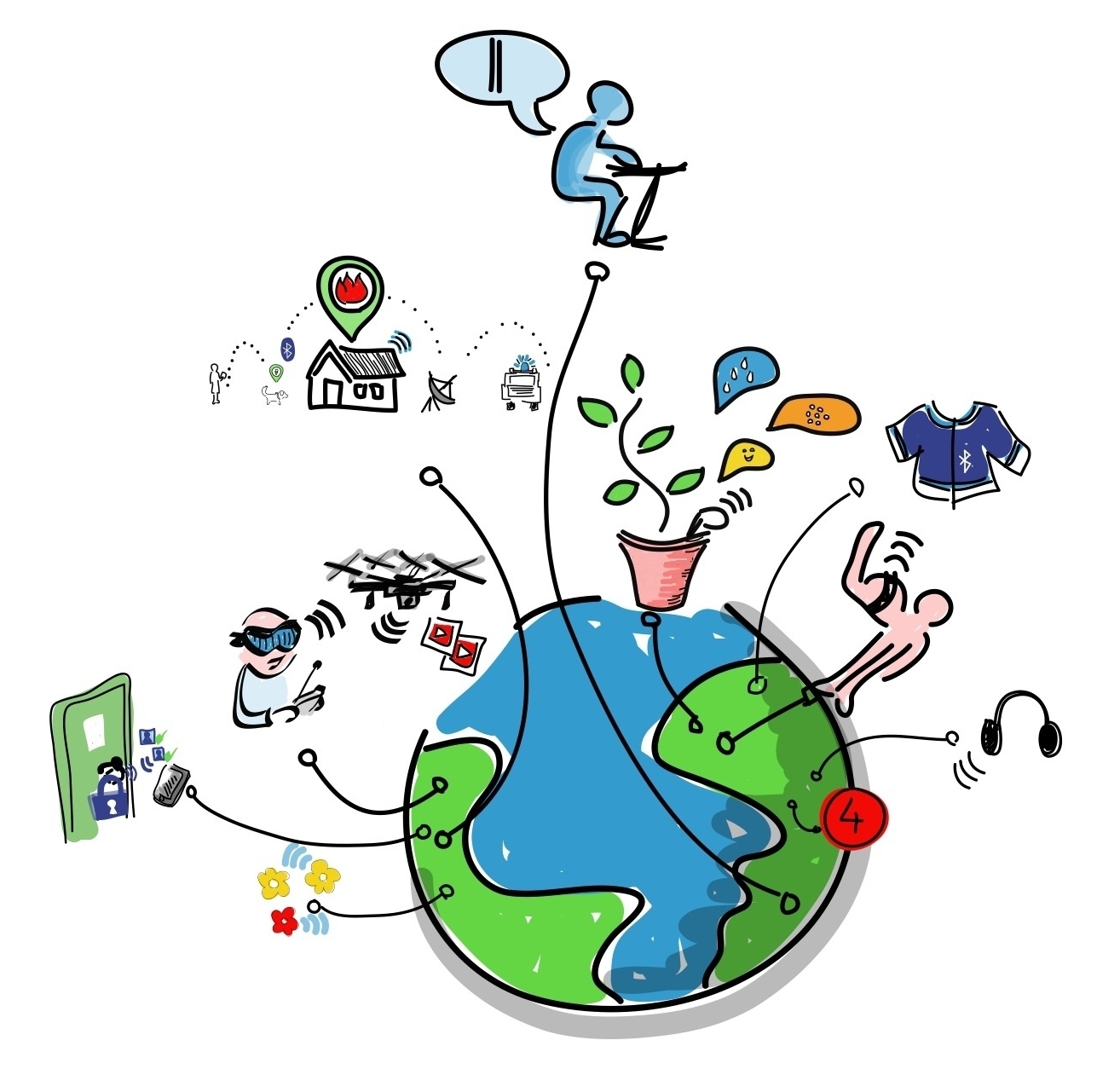
- IT permeates our life
- Internet of Things (IoT)
- From smart devices to smart cities
- How does that really work?
- Complexity? Functionality?
- Security? Privacy?
2. Distributed Systems
2.1. Definitions
A distributed system (DS) is …
- Leslie Lamport:
“one in which the failure of a computer you didn’t even know existed can render your own computer unusable”
(Lamport is Turing Award winner and (co-) author of seminal papers cited in this presentation)
![Photo of Leslie Lamport]()
“Photo of Leslie Lamport” under CC0 1.0; from Wikimedia Commons
- Tanenbaum and van Steen [TS07]: “a collection of independent computers that appears to its users as a single coherent system”
- Coulouris et al. [CDK+11]: “a system in which hardware and software components located at networked computers communicate and coordinate their actions only by passing messages”
- Thoughts, examples?
- Leslie Lamport:
“one in which the failure of a computer you didn’t even know existed can render your own computer unusable”

{kind=link}
{kind=link}
2.2. Internet vs Web
- (Preview on upcoming sessions)
- The Internet
is a network of networks
- Containing, e.g., our home networks, university networks, ISPs, etc.
- Connectivity for heterogeneous devices in DSs, regardless of their home network
- Connectivity enabled by various protocols
- IPv4 and IPv6 for host-to-host connectivity (IP = Internet Protocol)
- TCP and UDP for process-to-process connectivity (e.g., process of Web browser talks with remote process of Web server)
- TCP/IP to indicate a protocol stack, transmission of TCP data over IP
- Containing, e.g., our home networks, university networks, ISPs, etc.
- The Web
is an application using the Internet
- Clients and servers talk HTTP (another protocol) over TCP/IP
- E.g.,
GETrequests of HTTP ask for HTML pages (and more) - Web servers provide resources to Web clients (browsers, apps)
- E.g.,
- Clients and servers talk HTTP (another protocol) over TCP/IP
- Internet and Web are and contain DSs
- The Internet
is a network of networks
2.3. Technical DS Challenges
- No shared memory but message passing
- Concurrency
- Autonomy and heterogeneity
- Neither global clock nor global state
- Independent failures
- Hostile environment, safety vs security
2.4. DS Goals
- Make resources accessible
- E.g., printers, files, communication and collaboration
- Openness
- Accepted standards, interoperability
- Various distribution transparencies
2.4.1. Distribution Transparencies
- Transparency = Invisibility (hide complexity)
- Sample selection of transparencies from ISO/ODP [FLM95]
- Location t.: clients need not know physical server locations
- Migration t.: clients need not know locations of objects, which can migrate between servers
- Replication t.: clients need not know if/where objects are replicated
- Failure t.: (partial) failures are hidden from clients
2.4.2. Scalability
- Dimensions of scale
- Numerical: Numbers of users, objects, services
- Geographical: Distance over which system is scattered
- Administrative: Number of organizations with control over system components
- Typical scalability techniques
- (Scale up vs out)
2.4.3. Replication
- To replicate = to copy to multiple machines/nodes
- Copies (or nodes managing them) are called replicas
- E.g., manually forked and cloned repositories with Git or automatically managed redundancy with HFDS or Kubernetes
- Copies (or nodes managing them) are called replicas
- Effects
- Increased availability (usability in presence of faults)
- System usable as long as “enough” replicas available
- Reduced latency
- Use local or nearby replica
- Increased throughput
- Distribute/balance load among replicas
- Increased availability (usability in presence of faults)
- Challenge: Keep replicas in sync (consistent)
- Consensus required
2.4.4. Caching
- To cache = to save (intermediate) results close to client
- Temporary form of replication
- E.g., CPU caches keep data from RAM closer to CPU; in turn, RAM acts as cache for data from disk; in turn, disks act as caches for “cloud” data
- Temporary form of replication
- Effects
- Reduced load on server/origin
- Increased availability and throughput as well as reduced latency as with replication
- Challenge: Keep cache contents up to date
2.4.5. Partitioning
- To partition = to spread data or services among multiple
machines/nodes
- Each node responsible for subset
- (Sharding = partitioning in shared-nothing architecture)
- Effects
- Reduced availability: each node is additional point of failure
- If node fails, its data/services are not available
- (To improve availability, partitioning usually paired with replication)
- Reduced latency and increased throughput
- Each node operates on (small) subset
- (Partial) results on subsets produced fast; combined into overall result
- Nodes operate in parallel
- (Think of search in large set of data)
- Each node operates on (small) subset
- Reduced availability: each node is additional point of failure
2.5. Review Question
Prepare an answer to the following question
- How are replication, caching, and partitioning related to availability and scalability of distributed systems?
3. Models
3.1. System Models
- Distributed systems share important properties
- Common design challenges
- Models capture properties and design challenges
- Different types of models
- Physical models
- Computers, devices, and their interconnections
- Architectural models
- Entities (e.g., process, object, component), their roles and relationships (e.g., client, server, peer)
- Fundamental models
- E.g., interaction, consistency, security
- Physical models
- Abstract, simplified description of relevant aspects
- With different layers of abstraction (next slide)
- Different types of models
3.2. Layering
- Use abstractions to hide complexity
- Abstractions naturally lead to layering
- General technique in Software Engineering and Information Systems
- Alternative abstractions at each layer
- Abstractions specified by standards/protocols/APIs
- Thus, problem at hand is decomposed into manageable components
- Design becomes (more) modular
3.2.1. Hard- and Software Layers
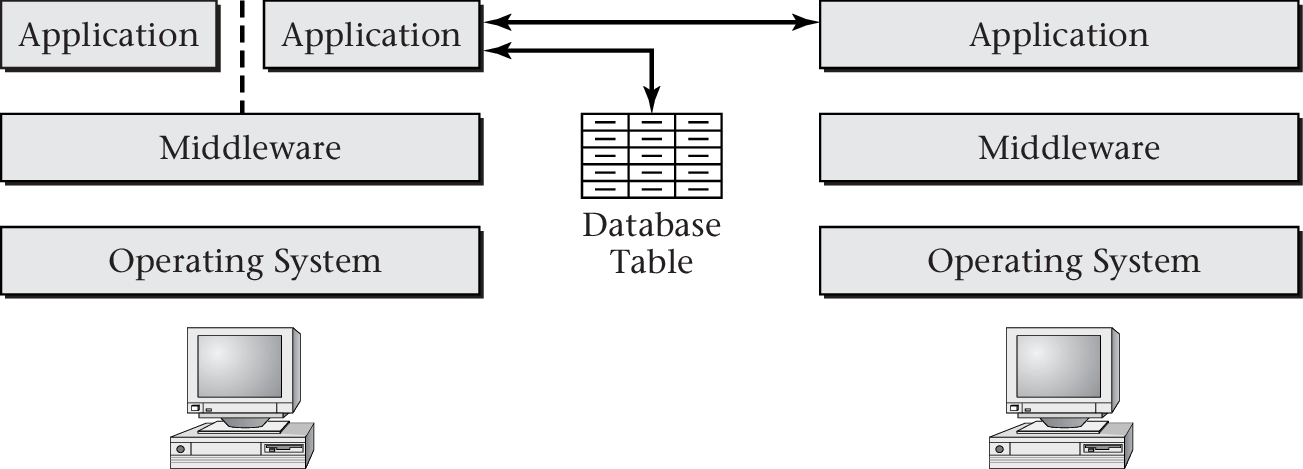
“Figure 1.2 of [Hai17]” by Max Hailperin under CC BY-SA 3.0; converted from GitHub
- OS provides API that hides hardware specifics
- Middleware provides API that hides OS specifics
- (Distributed) Applications use middleware API
3.2.2. Middleware
- Software layer for distributed systems
- Hide heterogeneity
- Provide convenient programming model
- Typical building blocks
- Remote method/procedure calls
- Group communication
- Event notification
- Placement, replication, partitioning
- Transactions
- Security
- Typical building blocks
- Examples beyond class goals
- ONC/Sun RPC, CORBA, Java RMI
- Web services via Service Oriented Architecture (SOA) or REST
3.2.3. Layered Network Models
- Upcoming session: Layering as core mechanism of network models
- ISO OSI Reference model with 7 layers
- Internet model with 4 layers
4. Time and Consistency
4.1. Clocks
- Every computer with own internal clock
- Used for local timestamps
- Every internal clock with own clock drift rate
- Clocks vary significantly unless corrections are applied
- Different correction approaches
- Alternatively, use logical time
4.2. Assumptions on Clocks and Timing
- Two extremes
- Asynchronous
- Nothing is known about relative timing
- Synchronous
- Time is under control, different processes can proceed in lock-step
- Asynchronous
- April 2018, HUYGENS, [G+18]: Time synchronization within tens
of nanoseconds based on machine learning
- (1 Nanosecond = 10-9 s)
4.2.1. Asynchronous Distributed System
- Completely asynchronous [FLP85]
- No assumptions about
- relative speeds of processes,
- time delay in delivering messages,
- clock drift.
- Thus,
- algorithms based on timeouts cannot be used,
- impossibility to tell whether some process has died or is slow.
- No assumptions about
- Fits the Internet
- Uncontrolled resource sharing implies unbounded delays.
- Solutions for asynchronous systems also work for synchronous ones.
4.2.2. Synchronous Distributed System
- Has known time bounds for
- execution of process steps,
- transmission of messages,
- clock drift rates.
- Major strength
- Algorithms can proceed within rounds.
- For every process, a defined behavior per round exists.
- Timeouts can be used to detect failures.
- Algorithms can proceed within rounds.
4.3. Logical Time
- Key insight of Lamport [Lam78]
- Events can be ordered via “happened before” relation
- Without reference to physical clock
- Giving rise to partial order of logical timestamps
- Events can be ordered via “happened before” relation
- Happened before, \(\to\)
- Each node/process knows order of local events
- Logical clock produces increasing non-negative integers as timestamps
- Sending of message, event \(s\), must have happened before receipt of that message, event \(r\), denoted by: \(s \to r\)
- Transitivity rule: If \(a \to b\) and \(b \to c\) then \(a \to c\)
- Each node/process knows order of local events
4.3.1. Sample Lamport Timestamps
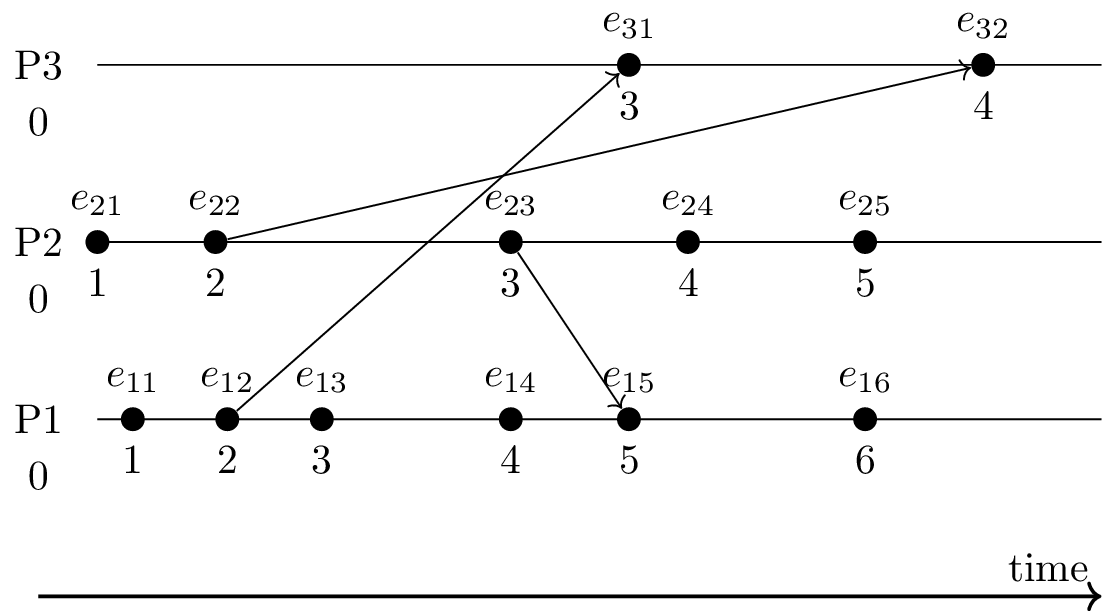
- Three processes: P1, P2, P3
- Each process with local clock (initially 0)
- Clock incremented for each event (including send/receive)
- Diagonal arrows represent messages
- Message includes timestamp of sender
- Receiver computes maximum of sender’s and own timestamp, increments result
- Each process with local clock (initially 0)
4.3.2. Lamport Timestamp Properties
- Consider events \(e\) and \(f\)
- Let \(l(e)\) and \(l(f)\) denote their Lamport timestamps
- If \(e \to f\) then \(l(e) < l(f)\)
- E.g., \(e_{11} \to e_{32}\) and 1 = \(l(e_{11}) < l(e_{32})\) = 4
- However, if \(l(e) < l(f)\) then we cannot conclude anything
- E.g., \(e_{32}\) “last” event but not largest timestamp (4 smaller than several other timestamps)
4.3.3. Vector Clocks
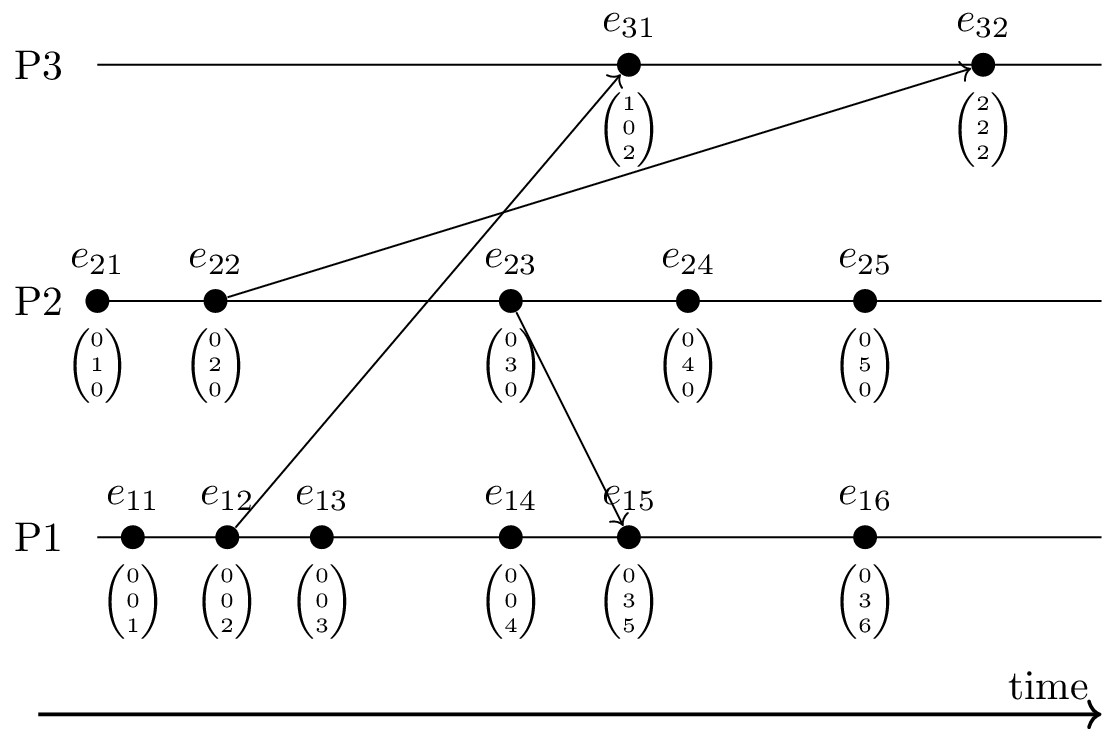
4.3.4. Vector Clocks and Happened Before
- Consider events \(e\) and \(f\)
- Let \(v(e)\) and \(v(f)\) denote their vector timestamps
- \(e \to f\) if and only if \(v(e) < v(f)\)
- (Here, “<” is component-wise comparison: At least one component is strictly smaller; others are less-or-equal)
- Conflicts/concurrency visible: incomparable vectors
- Actions at different locations without taking all previous events into account (e.g., \(e_{23}\) vs \(e_{14}\); merged at \(e_{15}\))
4.3.5. Review Questions
Prepare answers to the following questions
- Why are Lamport timestamps not sufficient to identify concurrent events?
- How could a continuation of the sample scenario for vector clocks look like such that all shown events are taken into account at all processes? How would the resulting timestamps look like?
4.4. Consistency
- Lots of different notions of consistency, e.g.:
- “C” in ACID transactions: Integrity constraints satisfied
- “I” in ACID transactions: Serializability
- All replicas have same value
- One formal criterion is linearizability
- Eventual consistency: If no updates occur for some time, all
replicas converge to the same value
- Vector timestamps to detect inconsistency
- Client-centric vs data-centric consistency: See text books
- Consistency requires distributed consensus/agreement
- Next slide
4.5. Consensus
Informal Statement
- Set of (distributed) processes needs to agree on value after some processes proposed values.
- E.g.:
- Who owns a lock?
- What is the current state of a replica?
- Who is the new primary server after a crash of the old one?
- Who owns a particular Bitcoin?
4.5.1. Byzantine Generals
- Famous consensus example:
Byzantine generals problem by Lamport, Shostak, Pease (1982) [LSP82]
- Three or more, possibly treacherous, generals need to agree whether to attack or to retreat
- Commander issues order, lieutenants must decide
- Treacherous commander may issue contradicting orders to lieutenants
- Treacherous lieutenants forward contradicting information to others
- If not all parties reach the same decision (consensus), the attack fails
- Nowadays, “Byzantine failure” is a standard term
- Arbitrary failure/misbehavior (hardware, software, attacks)
4.5.2. Results on Consensus
- Milestone results; \(N\) processes, \(f\) of them faulty
- [PSL80], synchronous systems: Solutions only if \(N \geq 3f + 1\).
- [FLP83],[FLP85], asynchronous systems: When \(f \geq 1\), consensus cannot be guaranteed.
- [Lam98] (submitted 1990):
Paxos algorithm for consensus in asynchronous systems
- State machine replication
- [Lam98]: “It does not tolerate arbitrary, malicious failures, nor does it guarantee bounded-time response.”
- State machine replication
- [CL99]: PBFT with digital signatures, \(N \geq 3f + 1\)
- [Bur06]: Chubby service (locking, files, naming)
- Implementing Paxos at heart of Google’s infrastructure
5. Conclusions
5.1. Summary
- Distributed systems are everywhere
- Internet as core infrastructure
- Networked machines coordinated with messages
- Various challenges and corresponding techniques
- Asynchronous distributed systems are built without global time
- Instead, logical timestamps, vector clocks
- Consensus is standard requirement in lots of scenarios
- Yet, consensus is hard in presence of failures
5.2. A Different Summary

Distributed systems
Figure © 2016 Julia Evans, all rights reserved; from julia's drawings. Displayed here with personal permission.
5.3. Concluding Questions
- What did you find difficult or confusing about the contents of the presentation? Please be as specific as possible. For example, you could describe your current understanding (which might allow us to identify misunderstandings), ask questions in a Learnweb forum that allow us to help you, or suggest improvements (maybe on GitLab). Most questions turn out to be of general interest; please do not hesitate to ask and answer in the forum. If you created additional original content that might help others (e.g., a new exercise, an experiment, explanations concerning relationships with different courses, …), please share.
Bibliography
- [Bur06] Burrows, The Chubby Lock Service for Loosely-coupled Distributed Systems, in: Proceedings of the 7th Symposium on Operating Systems Design and Implementation, 2006.
- [CDK+11] Coulouris, Dollimore, Kindberg & Blair, Distributed Systems: Concepts and Design, Addison-Wesley Publishing Company, 2011. https://www.cdk5.net/
- [CL99] Castro & Liskov, Practical Byzantine Fault Tolerance, in: Proceedings of the Third Symposium on Operating Systems Design and Implementation, 1999.
- [DHJ+07] DeCandia, Hastorun, Jampani, Kakulapati, Lakshman, Pilchin, Sivasubramanian, Vosshall & Vogels, Dynamo: Amazon's Highly Available Key-value Store, in: Proceedings of Twenty-first ACM SIGOPS Symposium on Operating Systems Principles, 2007. https://doi.acm.org/10.1145/1294261.1294281
- [FLM95] Farooqui, Logrippo & de Meer, The ISO Reference Model for Open Distributed Processing: an introduction, Computer Networks and ISDN Systems 27(8), 1215-1229 (1995). http://www.sciencedirect.com/science/article/pii/016975529500087N
- [FLP83] Fischer, Lynch & Paterson, Impossibility of Distributed Consensus with One Faulty Process, in: Proceedings of the 2Nd ACM SIGACT-SIGMOD Symposium on Principles of Database Systems, 1983. https://doi.acm.org/10.1145/588058.588060
- [FLP85] Fischer, Lynch & Paterson, Impossibility of Distributed Consensus with One Faulty Process, J. ACM 32(2), 374-382 (1985). https://doi.acm.org/10.1145/3149.214121
- [G+18] Geng, Liu, Yin, Naik, Prabhakar, Rosenblum & Vahdat, Exploiting a Natural Network Effect for Scalable, Fine-grained Clock Synchronization, in: 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18), 2018. https://www.usenix.org/conference/nsdi18/presentation/geng
- [Lam78] Lamport, Time, Clocks, and the Ordering of Events in a Distributed System, Commun. ACM 21(7), 558-565 (1978). https://doi.acm.org/10.1145/359545.359563
- [Lam98] Lamport, The Part-time Parliament, ACM Trans. Comput. Syst. 16(2), 133-169 (1998). https://doi.acm.org/10.1145/279227.279229
- [LSP82] Lamport, Shostak & Pease, The Byzantine Generals Problem, ACM Trans. Program. Lang. Syst. 4(3), 382-401 (1982). https://doi.acm.org/10.1145/357172.357176
- [Neu94] Neuman, Scale in Distributed Systems, in: Readings in Distributed Computing Systems, IEEE Computer Society Press, 1994. https://web.archive.org/web/20210614151431/http://clifford.neuman.name/publications/
- [PPR+83] Parker, Popek, Rudisin, Stoughton, Walker, Walton, Chow, Edwards, Kiser & Kline, Detection of mutual inconsistency in distributed systems, IEEE transactions on Software Engineering SE-9(3), 240-247 (1983). http://doi.ieeecomputersociety.org/10.1109/TSE.1983.236733
- [PSL80] Pease, Shostak & Lamport, Reaching Agreement in the Presence of Faults, J. ACM 27(2), 228-234 (1980). https://doi.acm.org/10.1145/322186.322188
- [RS95] Raynal & Singhal, Logical Time: A Way to Capture Causality in Distributed Systems, INRIA, (1995). https://hal.inria.fr/inria-00074203
- [TS07] Tanenbaum & Steen, Distributed Systems: Principles and Paradigms, Prentice-Hall, Inc., 2007.
License Information
This document is part of an OER collection to teach basics of distributed systems. Source code and source files are available on GitLab under free licenses.
Except where otherwise noted, the work “Distributed Systems”, © 2018-2023 Jens Lechtenbörger, is published under the Creative Commons license CC BY-SA 4.0.
In particular, trademark rights are not licensed under this license. Thus, rights concerning third party logos (e.g., on the title slide) and other (trade-) marks (e.g., “Creative Commons” itself) remain with their respective holders.