Interrupts and I/O II
(Usage hints for this presentation)
IT Systems, Summer Term 2026
Dr.-Ing. Matthes Elstermann
1. Introduction
- Part 1
- Break for self-study
- Part 2
2. I/O Processing Variants
2.1. Recall: I/O with Interrupts
-
- Asynchronous processing of I/O
- External notifications via interrupts
![I/O with Interrupts]()
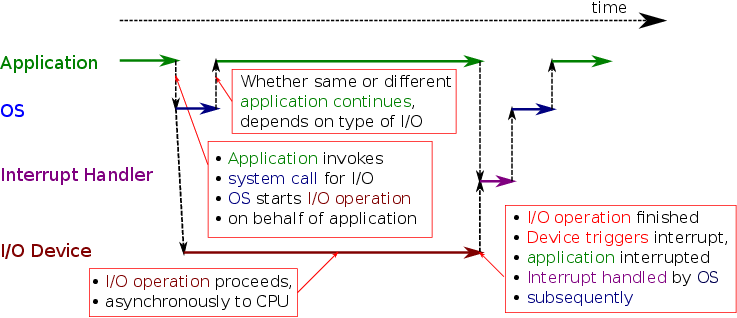
2.2. Blocking vs Non-Blocking I/O
Previous slide left open which application continues after I/O system call
OS provides blocking and non-blocking system calls
Blocking system call
- Thread invoking system call has to wait (is blocked) until I/O completed
- However, a different thread may continue
- Scheduling, context switch, overhead
- Non-blocking system call
- OS initiates I/O and returns incomplete result to thread
- Thread continues (and is informed of or needs to check for I/O completion at later point in time)
- (Notice: This is impossible with polling)
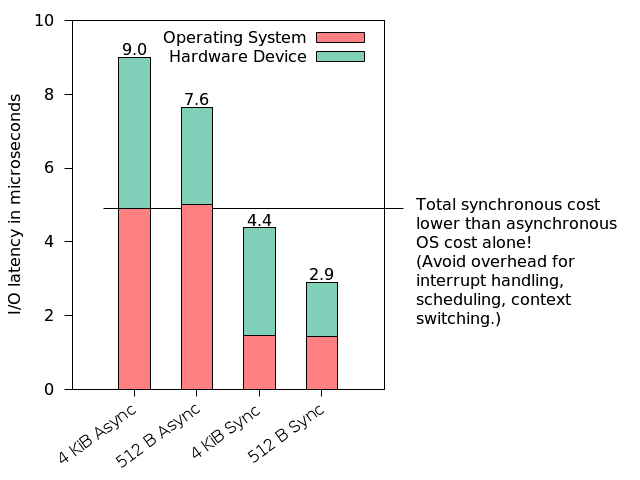
2.3. Latency Example (1/2)
- Goal: Explain interrupt overhead as serious challenge if interrupts are frequent
- See (Larsen et al. 2009)
- Two PCs with Intel Xeon processors (2.13 GHz)
- 1 Gbps Ethernet networking cards connected via PCIe
- 1 – 2 frames may arrive per 1 µs (1 µs = one millionth second)
- For the curious
- Ethernet’s unit of transfer: frame with minimum size of 512 b
- At 1 Gbps, 1000 b need 1 µs for transfer, plus propagation and queueing delays
- Thus, 1 – 2 frames may arrive per 1 µs
- For the curious
- Interrupt per frame arrival!?
- What about 10 Gbps networking?
2.4. Latency Example (2/2)
- Numbers from (Larsen et al. 2009)
- Processing of single frame takes total of 7.7 µs
- Latency breakdown according to different sources
- Hardware: ≈ 0.6 µs
- Interrupt processing: > 3 µs
- Processing of data: > 3 µs
- If one or two frames arrive per 1 µs and each frame needs 7.7 µs
processing time, something is seriously wrong
- Network data will be dropped because it arrives too fast
- The system could even crash
- Interrupt per arrival does not work
- Network data will be dropped because it arrives too fast
2.5. Interrupt Livelocks
- Livelock: Situation in which computations take place but (almost)
no progress is made
- Computation time is mostly wasted on overhead
- Interrupt livelock
- Interrupts arrive so fast that they cannot be processed any longer
- Also, not enough CPU time left for other tasks
- Interrupts served with high priority
- Context switching, cache pollution
- Nothing useful happens any more
- Also, not enough CPU time left for other tasks
- Prevent by hybrid of polling and interrupts
- E.g., NAPI (New API)
- Interrupts arrive so fast that they cannot be processed any longer
2.5.1. Starvation
- Interrupt livelock is special case of starvation
Starvation = continued denial/lack of resource
- Under interrupt livelock, threads do not receive resource CPU (in sufficient quantities for progress) as long as “too many” interrupts are triggered
Starvation revisited in later presentations on scheduling and challenges for mutual exclusion
2.6. NAPI
- NAPI: Linux “New API” for networking
Hybrid scheme
Use interrupts under low load
- Utilize CPUs better
- Avoid polling for devices without data
- Utilize CPUs better
Switch to polling under high load
- Avoid interrupt overhead
- Data will be available anyways
- Avoid interrupt overhead
See (Cai and Karsten 2023) for performance improvement proposed in 2023
- Merged into kernel in 2024
- May reduce energy consumption in datacenters by 30%
3. Outlook
3.1. When to Poll?
3.2. I/O Processing – Then and Now
- Then: Disks are slow
- Mechanical devices
- Delivered data is processed immediately by CPU
- Latency before data arrives → Interrupts beneficial
- Now: Nonvolatile memory is fast, see (Nanavati et al. 2016)
- Mechanics eliminated
- Operation at network/bus speed (PCIe)
- Data can be delivered faster than processed → Polling beneficial
- Need to rethink previous techniques
- Balancing, scheduling, scaling, tiering
3.3. Call for Research
(Barroso et al. 2017): Attack of the Killer Microseconds
Nanosecond latency (DRAM access when data not in CPU cache) is hidden by CPU hardware
- Out-of-order execution, branch prediction, multithreading (two threads per core)
- (However, also ongoing research to address Killer Nanoseconds (Jonathan et al. 2018))
Millisecond latency (disk I/O) is hidden by OS
- Multitasking
What about microseconds of new generation of fast I/O devices?
- E.g., Gbps networking, flash memory
- Paper describes datacenter challenges experienced at Google
4. Conclusions
4.1. Summary
- Interrupt handling is major OS task
- I/O processing
- Timers, to be revisited for scheduling
- System call implementation
- Polling vs interrupt-driven I/O
- Efficiency trade-off
- Interrupt livelocks and NAPI
Bibliography
License Information
Source files are available on GitLab (check out embedded submodules) under free licenses. Icons of custom controls are by @fontawesome, released under CC BY 4.0.
Except where otherwise noted, the work “Interrupts and I/O II”, © 2017-2026 Jens Lechtenbörger, is published under the Creative Commons license CC BY-SA 4.0.